Hi there
This was originally a question for “Help” section, but we fixed it in between, so here’s a performance feedback. We run our services on EKS, and routing wise it’s Internet ==> Contour / Envoy ingress controller ===> reverse proxy ===> service.
We swapped the reverse proxy from Nginx to Caddy today. The reason was a bunch of outage we had due to Nginx DNS resolution, and we wanted to benefit from Caddy’s rate limiting plugin too.
Just after the swap, our alert fired over the CPU consumption for our api backend service (~25 pods, 500req/sec). Our first idea was the load balancing policy, defaulting to “random”. So we went for “round robin”, than “least conn”, no success. Then we disabled keep alive, and that was it. Note that Nginx was running 6 pods, Caddy ran 3 pods until we disabled keepalive, then it scaled to 6 pods too (adjusted by Horitontal Pod Autoscaler over CPU usage)
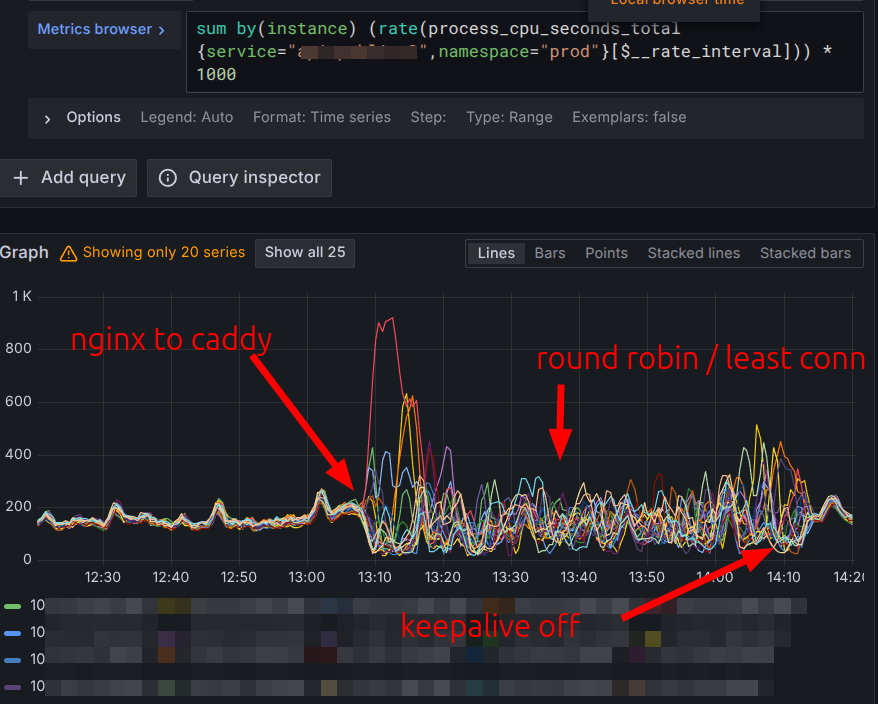
Conclusion, no big difference resource wise before & after. But a way better DX overall (available metrics, documentation, syntax …), and some neat features (rate limiting, replacing Api-Key header with REDACTED, etc)
Thanks for Caddy ![]()