1. Output of caddy version:
Not yet using Caddy but will run the latest
2. How I run Caddy:
Will run on Debian machines potentially in a cluster using Redis to store certificates
a. System environment:
Will run Caddy under systemd likely and be on bare metal running Debian (Unsure what version, sorry!)
b. Command:
Unsure yet
c. Service/unit/compose file:
Will likely be the default service file (not yet confirmed)
d. My complete Caddy config:
The config will likely look something like this (yet to implement):
subdomain1.example.com {
handle /wss* {
reverse_proxy app1:4000
}
reverse_proxy app2:4001
}
subdomain2.example.com {
handle /wss* {
reverse_proxy app1:4002
}
reverse_proxy app2:4003
}
<repeat a large amount of times>
3. The problem I’m having:
Hi all! First off I’m not having a problem with Caddy but looking at getting some advice to see whether it will have the same problem Nginx does. I am also not trying to start a Nginx vs Caddy argument, just trying to understand whether it will have the same issue.
A friend of mine is running a medium sized operation that has a few Nginx “gateway” servers that proxy traffic to application servers sitting behind it. Excuse the spaghetti but hopefully this diagram makes some sense to describe the setup.
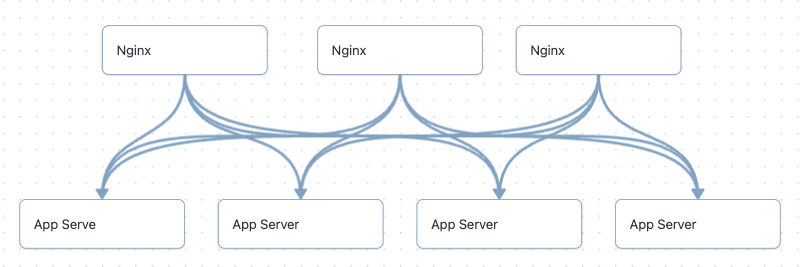
This setup works fine but runs into an issue when reloading Nginx. The application running on this setup uses long lived websocket connections to give live updates to clients. When reloading Nginx to do config updates these requests don’t die so workers end up staying around. This leads to higher memory usage on every reload (~500MB each time, give or take 50MB or so) and eventually a full restart is required to get the memory usage back under control which sucks because it essentially means you have an outage.
Nginx’s solution is to set a worker_shutdown_timeout so that the older workers do eventually shutdown even if there are still websocket connections active but this obviously breaks those connections.
Reloads need to happen somewhat frequently as new servers or application instances are added/removed.
I understand why this needs to happen with Nginx so what I’m trying to understand is whether Caddy reloads would run into this same limitation? The setup would be running on Debian and we can use the Admin API to either push updates or more than likely just let Caddy push updates to a Caddyfile change through the default systemd handler.
Does Caddy need to fork new child procs to handle new configurations or does it hot load the new config into the proc somehow? Hopefully what I’m asking makes sense but please let me know if not!
I also want to state I completely understand all of the other amazing features Caddy can bring to the table to help this setup. At the moment this current issue is the most pressing but Caddy’s handling of certificates will also be a major focus in the future if thats relevant. A Caddy migration would be ideal and likely, just want to make sure I understand if we need to add some special handling for this particular issue like moving websocket connections to a dedicated domain like wss.example.com or something.
4. Error messages and/or full log output:
N/A
5. What I already tried:
Nothing yet, just seeking information!
6. Links to relevant resources:
- Nginx docs on worker shutdown timeout Core functionality