So I’ve studied @matt’s wiki article Load balancing Caddy and after further research began to realise that, for a home network, there are a couple of issues:
- It is not necessarily a viable proposition to place Caddy behind a h/w or cloud-based load balancer; and
- Sharing storage between two Caddy RPs could be problematic as the shared storage itself is a single point of failure.
It’s still worthwhile considering setting up a redundant RP on a separate h/w server particularly if there are lots of upstream services. I wonder if a second Caddy RP could be set up in a ‘cold standby’ mode and swung into operation on failure on the primary RP? Storage is local to the RP, but could be replicated. Visually, it would look like this…
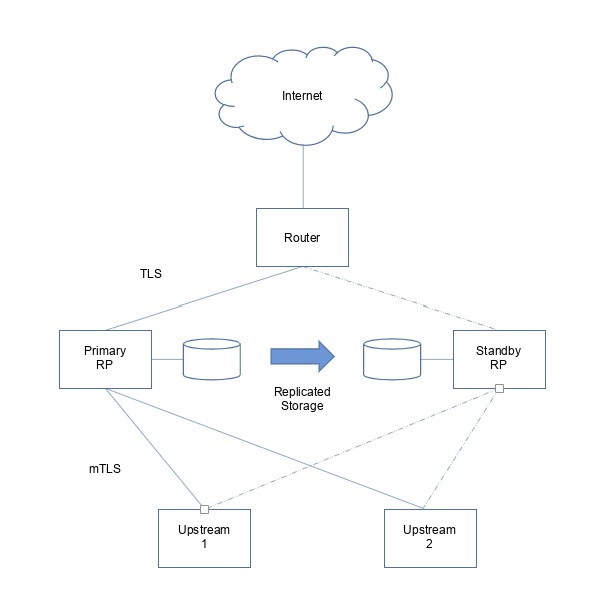
Is this a reasonable way to proceed? Assuming it is, the question I have is around the storage replication schedule. Let’s say local storage is replicated every 15 minutes. Just before the next replication event, the primary RP fails and the standby RP is swung into operation. There’s a potential loss of 15 minutes of ‘something’ on the replicated storage. What is the impact, if any, on mTLS or will it just sort itself out through the issue of new internal certificates?